
錦です。
Appleは昨夜開催されWWDCの基調講演、そしてその後のPlatform State of Unionにて、Metal 3を正式に発表しました。
Metal 3
MetalはAppleデバイスで動作するグラフィックスAPIです。今回の重要なテーマとなっているのは「Apple Siliconへの最適化」と「ゲーム機能の強化」のようです。Appleがゲームに注力している象徴となっています。

Metal 3の新機能は6つの要素で構成されています。
今回特に重要視スべきなのは、MicrosoftのDirectX 12 UltimateやAMDのFidelityFXのような機能が実装されている点です。順番は前後しますが、それぞれの項目を見ていきます。
MetalFX Upscaling
「MetalFX Upscaling」では、豊かで視覚的に複雑なシーンのレンダリングをより早く行えるようになります。Upscalingと書かれていることから、超解像技術であることがわかりますね。
現在、有名なところでの超解像度技術がNVIDIAの「Deep Learning Super Sampling」(DLSS)、AMDの「FidelityFX SuperResolution」(FSR)、Intelの「Xe SuperSampling」(XeSS)があり、これらは「機械学習ベース」か「フィルタベース」かの大きく2つに分けることができます。実際に分けると、DLSSとXeSSは機械学習ベース、FSRがフィルタベースとなり、AppleのMetalFX Upscalingはどちらかというとフィルタベースの超解像技術になるようです。
フィルタベースの超解像技術は、再構成法という技術に基づく超解像技術で、具体的にはピクセルを分割したときの平均と、周辺のピクセルから予想して、ピクセルを生成します。AMDはこれをFidelityFXライブラリ内のオープンソースで行っているので、フィルタと表現していますが、Appleが実際にフィルタとして実装しているかは不明です(つまりフィルタベースという言葉自体は便宜上用いているにとどまります)。
ところで、Apple Siliconには機械学習用のアクセラレータ(NPU?)としてNeural Engineが搭載されていますが、これは活用されない様子。
UMAのせいでわかりにくくなっていますが、Neural EngineはGPUと同じレベルに配置されているアクセラレータとなっており、そもそもRTコアやXMXと違ってGPUにマウントされていないためワークフローの中に取り込めないのかもしれません。
後でお話しますが、Metal 3は基本的にApple Siliconをターゲットにしていますが、一部のRadeonやIntel GPUでも動作するので、その観点からNeural Engineに絞ることができなかったのかもしれませんね。
MetalFX Upscalingについてはセッション「Boost performance with MetalFX Upscaling」で詳細が語られています。
MetalFX自体は、FidelityFXと同様に開発者に対して最適なグラフィック効果を提供するAPIであり、MetalFX Upscalingはその中の一つです。MetalFX Upscalingには2種類の超解像方法があり、空間アップスケーリングと時間軸を基にしたアンチエイリアスによるアップスケーリングです。
Appleは空間的なアップスケーリングを用いることで、簡単にパフォーマンスを向上させることができ、アンチエイリアスによるアップスケーリングではより高品質な出力を得ることができるとしています。
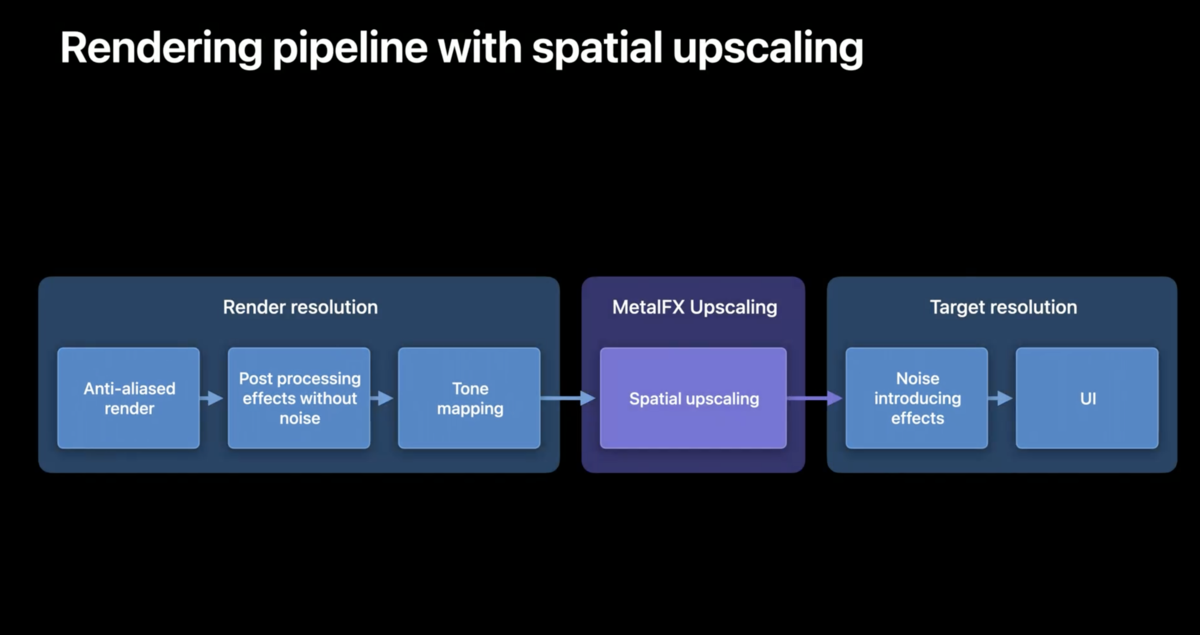
レンダリングパイプラインを用いて説明されたものを見ると、アンチエイリアスレンダリングとポストエフェクト処理、トーンマッピングプロセスの後にMetalFX Upscalingを投入します。MetalFX Upscalingに入力する時点でトーンマッピングが終了していれば、知覚的な色空間を基にアップスケーリングを処理します。
パストレースされたチェスによるデモを見ると、960x540で入力された映像が、MetalFX Upscalingによって1920x1080つまりフルHDにアップスケーリングされています。少なくとも4倍スケールが可能であるということがわかりました。
空間的なアップスケーリングは、ゲームなど品質より速度・パフォーマンスを求める場面でのアップスケーリング技術で、低負荷で高解像度化するというよりかは、同じ解像度のままFPSを向上させるのが主な目的であると考えられます。一方で、時間軸を基にしたアンチエイリアス(Temporal Anti-Alias and Upscaling/TAAU)によるアップスケーリングは、品質を重視したアップスケーリングとなります。
TAAUでは、そのフレームのみの空間情報を基にアップスケーリングを行っていましたが、時間軸を基にした場合、前のフレームのアップスケーリング結果と今回のレンダリング結果の両方を基にアップスケーリングを行います。具体的にはサンプリングします。
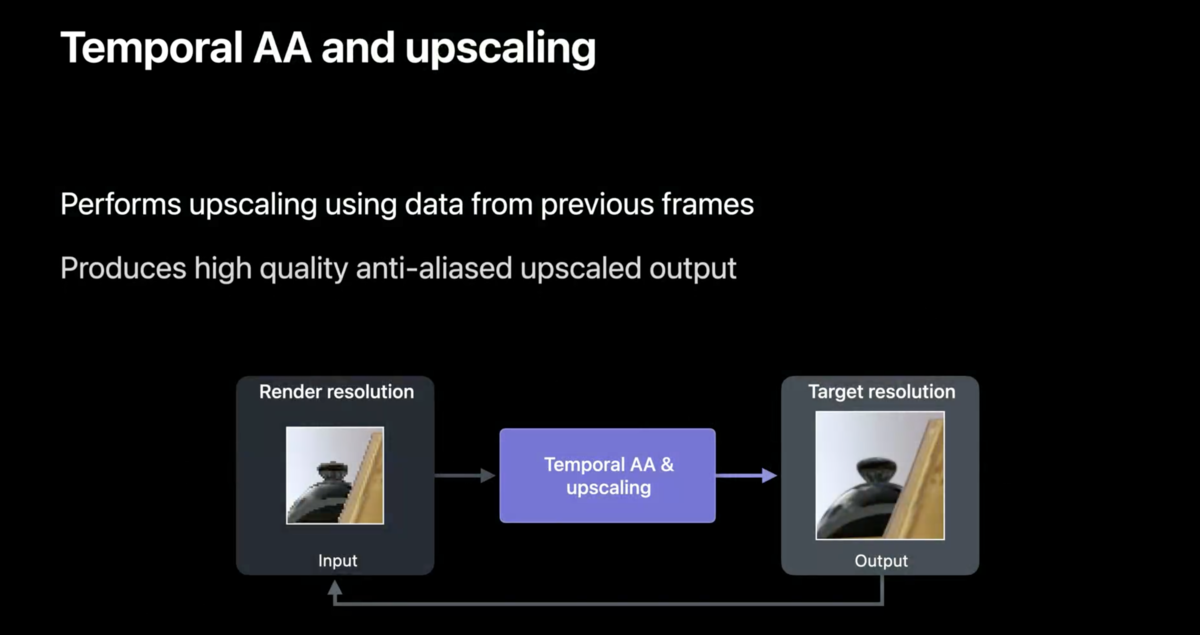
サンプリングは、基本的多くのデータがある方がより正確です。つまり、このアップスケーリング手法もデータが多いほうがいいわけです。ただし、多くのサンプルを用意すればするほど、コストがかかります。そこで登場するのが、時間軸アンチエイリアスです。時間軸サンプリングは、特定のフレーム内のすべてのピクセルに対して異なるサンプル位置をレンダリングするという概念です。これにより、大幅に低いコストで複数のフレームにわたってスーパーサンプリング品質を実現できます。複数のフレームからサンプルを蓄積し、サンプルの位置を考慮することにより、時間的AAとアップスケーリングにより、サンプルをターゲット解像度のピクセルに適切に統合でき、高品質のアンチエイリアスアップスケール出力が得られます。
時間軸アンチエイリアスでは、前のフレーム・ジッターのあるカラー入力・モーション・深度情報が必要です。ジッターのあるカラー入力については、フレームに於いてサンプリングする場所に関係ある・・・みたいですが、詳細なことは理解できませんでした。前のフレームが必要な理由はサンプリングするためです。モーションの入力によって、前のフレームからの移動を計算します。深度情報では、そのシーンにおいて、前面にあるものと背面にあるものを区別します。これらの色・前のフレームからの移動・フレームに於いての位置関係といったデータを基にサンプリングしてアップスケーリングするのがTAAUです。
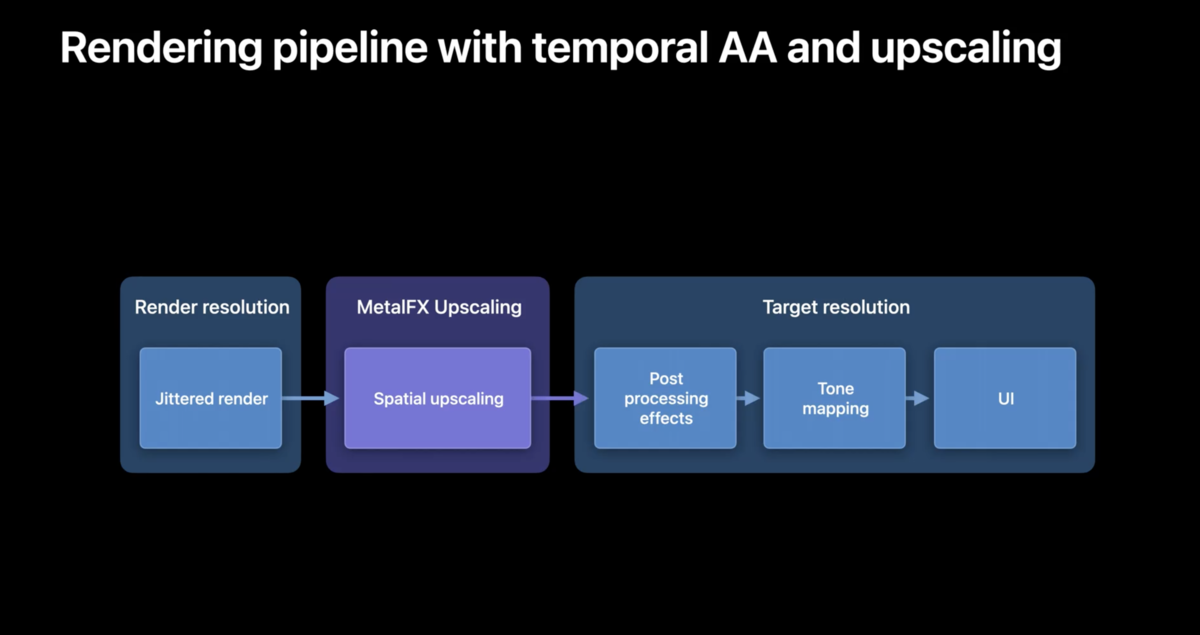
実装部分については、前述の通りジッターカラーが必要なので、ジッターのレンダリングはアップスケーリングの前に用いる必要があるものの、ポストエフェクト後に行うと干渉する可能性があるので、ポストエフェクトよりも先に組み込む必要があります。
スケールの最大倍率は不明なものの、デモではフルHDから4Kへ4倍スケールがデモされています。ちなみに、こちらもアップスケーリング技術ではあるため、ネイティブでフルの解像度を出すよりFPSは向上します。ただ、FPSを追求するなら空間アップスケーリング(SU)を用いたほうがいいです。
性能は SU > TAAU > ネイティブ
品質は ネイティブ > TAAU > SU
と考えたらいいでしょう。
Fast resorce loading
ゲームにおいてロードが長いというのはストレスになりえます。
Fast resource loadingでは、ロードを分割するといっては異なると思いますが、ストレージからストリーミングする形でロード時間を短縮するという方式です。現在のストレージAPIは、大規模なリクエストを一括して要求する形にできていますが、それを細かくするという感じです。
Fasr resource loadingはセッション「Load resources faster with Metal 3」で語られています。
目的が似た技術として、他社のDirect Strageのようなものがあります。こちらは、ストレージからCPUをパスして直接ビデオメモリにデータをロードする機能です。対して、Apple SiliconではUMAを採用しているため、そもそもビデオメモリという概念はありません。目的は似ていても技術の中身は全く異なります。
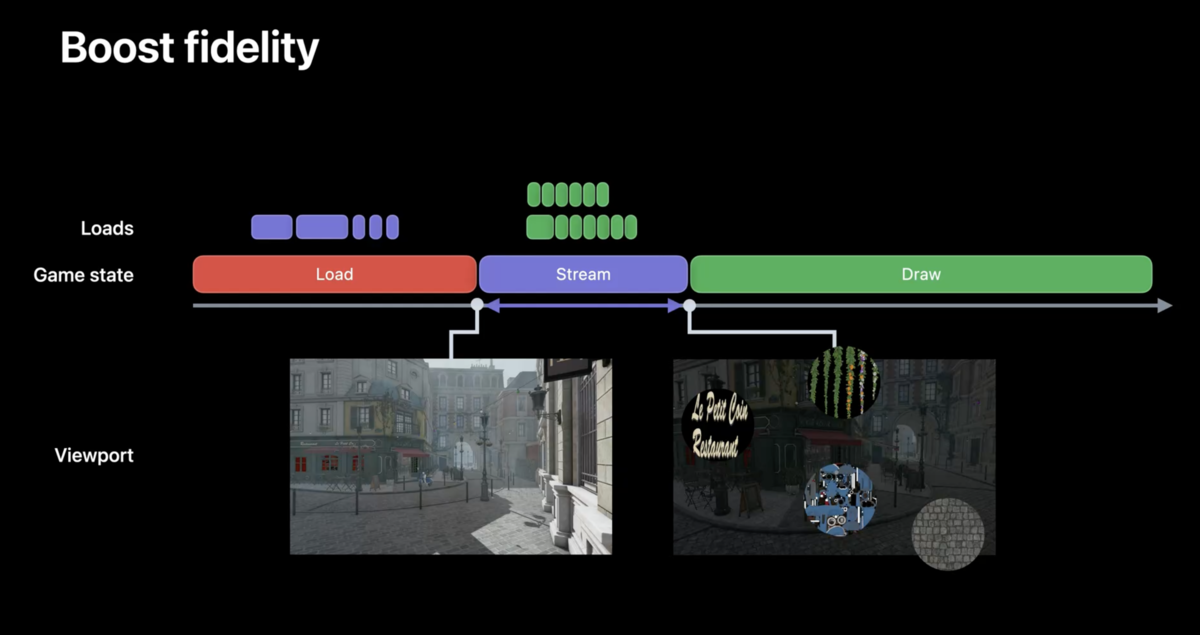
話を戻します。ロード時間を小さくする方式としては、ゲームの開始時にロードするのは起動に必要なデータのみで、シーンのアセットなどはプレイヤーがオブジェクトに近づいたら必要なリソースをストリーミングするという方式があります。もっと具体的な例を上げれば、ゲーム開始時点で離れている黒板をその時点では非常に荒いアセットで生成します。その後、プレイヤーが黒板に近づくことでリソースをストリーミングして、黒板に書かれているものなどを高画質化します。
ただし、この方法では、高解像度の黒板自体をロードするのに時間が掛かる可能性があります。
Fast resource loadingの最大の特徴は、アセット単位ではなく、アセットよりも小さな単位でロードを要求できる様になることです。もちろん、最終的にロードするデータの量というのは変わりませんので、ロードを分ける分、ストレージに対するリクエストも増加しますが、最新のストレージハードウェアは一度に複数のリクエストを処理できるように設計されているので問題はありません。
オフラインコンパイル
オフラインコンパイルはセッション「Target and optimize GPU binaries with Metal 3」で語られています。
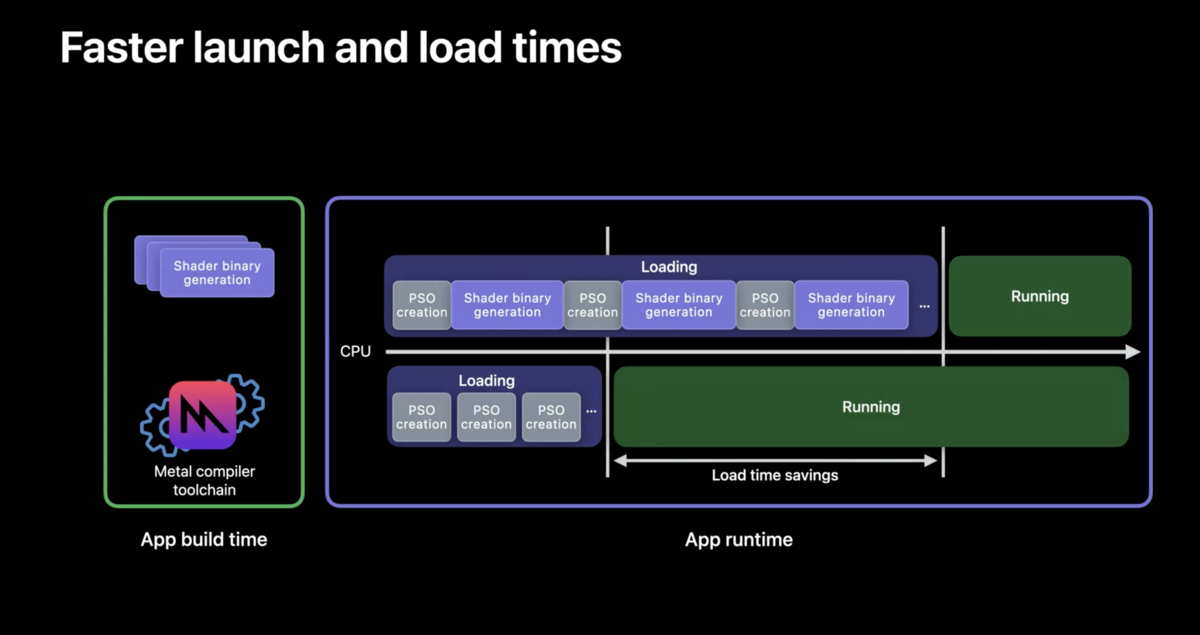
通常、MetalではGPUバイナリの生成はプロジェクトのビルド時と実行時に行われます。超簡単にオフラインコンパイルの解説をします。実行時のバイナリ生成をビルド時に持っていく方式です。これによって、ロード時の待機時間を大幅に減らすことができます。バイナリ自体はMetalによってキャッシュされるので、頻繁にコストが掛かることはありません。
また、従来のGPUバイナリ生成はロード時だけでなく、実際のプレイ中にも行われる事があり、かつバイナリ生成は軽量な処理ではなかったのでこの処理においてフレーム落ちが発生していました。それも削減されます。
なお、アプリの初回実行などでバイナリが必要になった場合はバイナリが生成されることがあり、全てのバイナリ生成が削減されたわけではないというのを追記しておきます。
レイトレ
レイトレの強化はあくまでもレイトレーシングを生成する機能の最適化であり、リアルタイムレイトレーシングと同義であるわけではないことに注意が必要です。
このレイトレの強化についてはセッション「Maximize your Metal ray tracing performance」で語られています。
Metal 3では、CPUとGPUの処理時間を大幅に削減し節約します。そもそもApple Siliconを始めMac GPUなどはレイトレ用のアクセラレータを持っているわけではないので、光線(レイ)の描画と追跡に時間をさける様になったことはとても素晴らしいことです。
また、Metal自体にレイトレのための新しいコマンドが追加されたことによって、カリングなどのCPU処理部分をGPUに移すことができCPUの処理も軽減されます。
その他多くの最適化がありますが(専門的すぎて理解が追いつかないため)割愛します。やる気があったら更新します。(メッシュシェーダーも割愛)
機械学習
機械学習については、Metalでも強化されていますが、実際にはGPUのみならずシリコン全体として強化されています。
Metal 3での大きな変更点は、Mac GPUによるPyTorchのGPUアクセラレーションのサポートです。PyTorch 1.12でMacに搭載されたGPUを用いてアクセラレーションすることができます。
また、Apple Silicon向けでのアップデートとしてはトレーニング性能がかなり強化されています。PyTorchとApple GPUを用いてトレーニングを行うと、M1 Ultraで最大20倍のスピードアップ、平均でも8.3倍の速度向上が見られたとのことです。
Tensor Flow Metalが強化され、Mac Studio単体でResNet50モデルのトレーニングの向上が果たせるようになったほか、Tensorflow Metalプラグインには、argMin、all、pack、adaDeltaなど、さまざまな新しい操作のためのGPUアクセラレーションが搭載されています。
対応機種
対応機種は、iPhoneならiPhone 11以降、iPadなら、iPad Air 4よりもあとに発表されたモデル、Macについては以下のGPUが搭載されたモデルとなっています。
また、Metal 3とMetalFX Upscalingを採用した、バイオハザード・ビレッジが今年後半にMacで登場します。
関連リンク
- セッション「Discover Metal 3」